Abstract
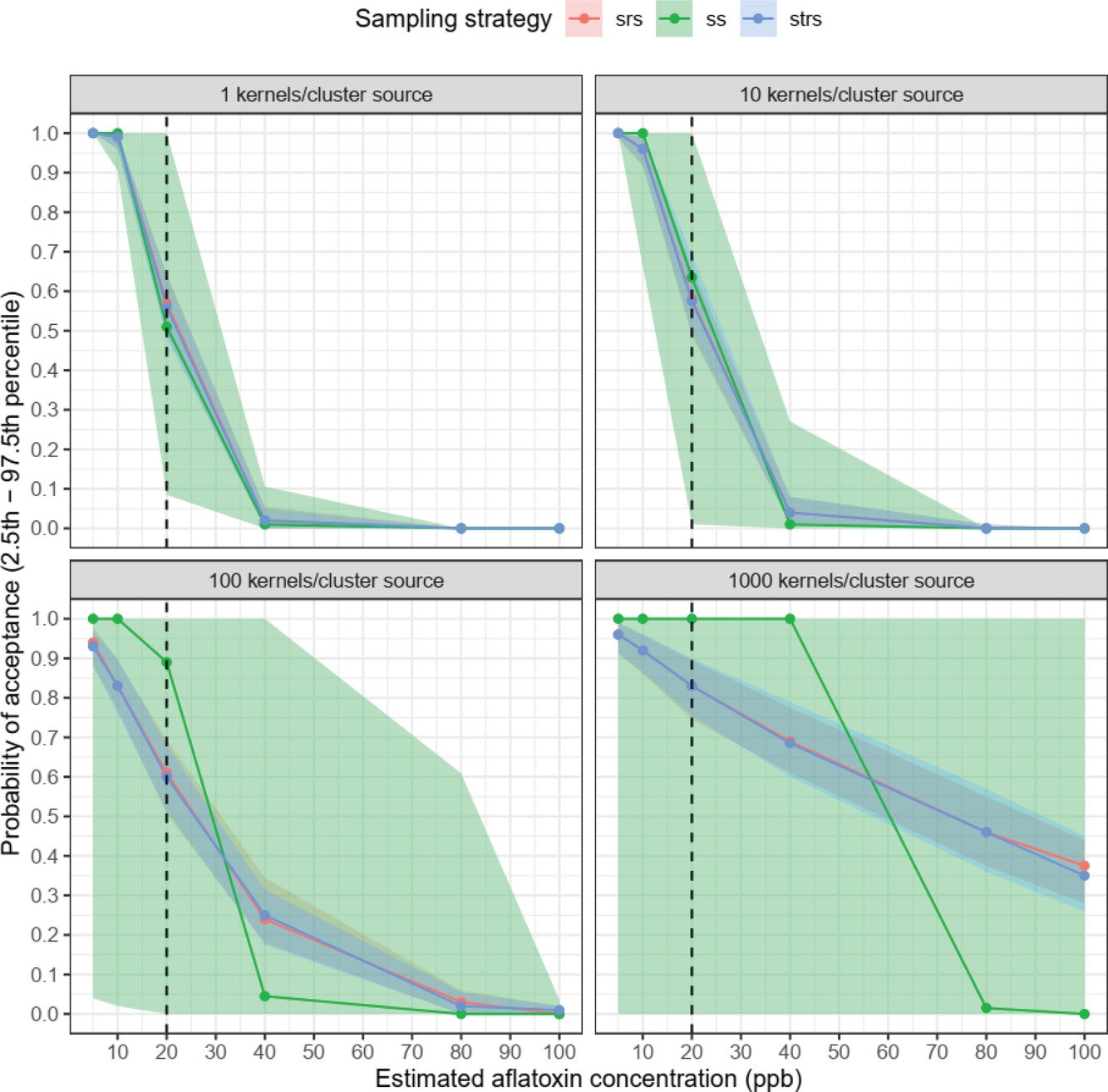
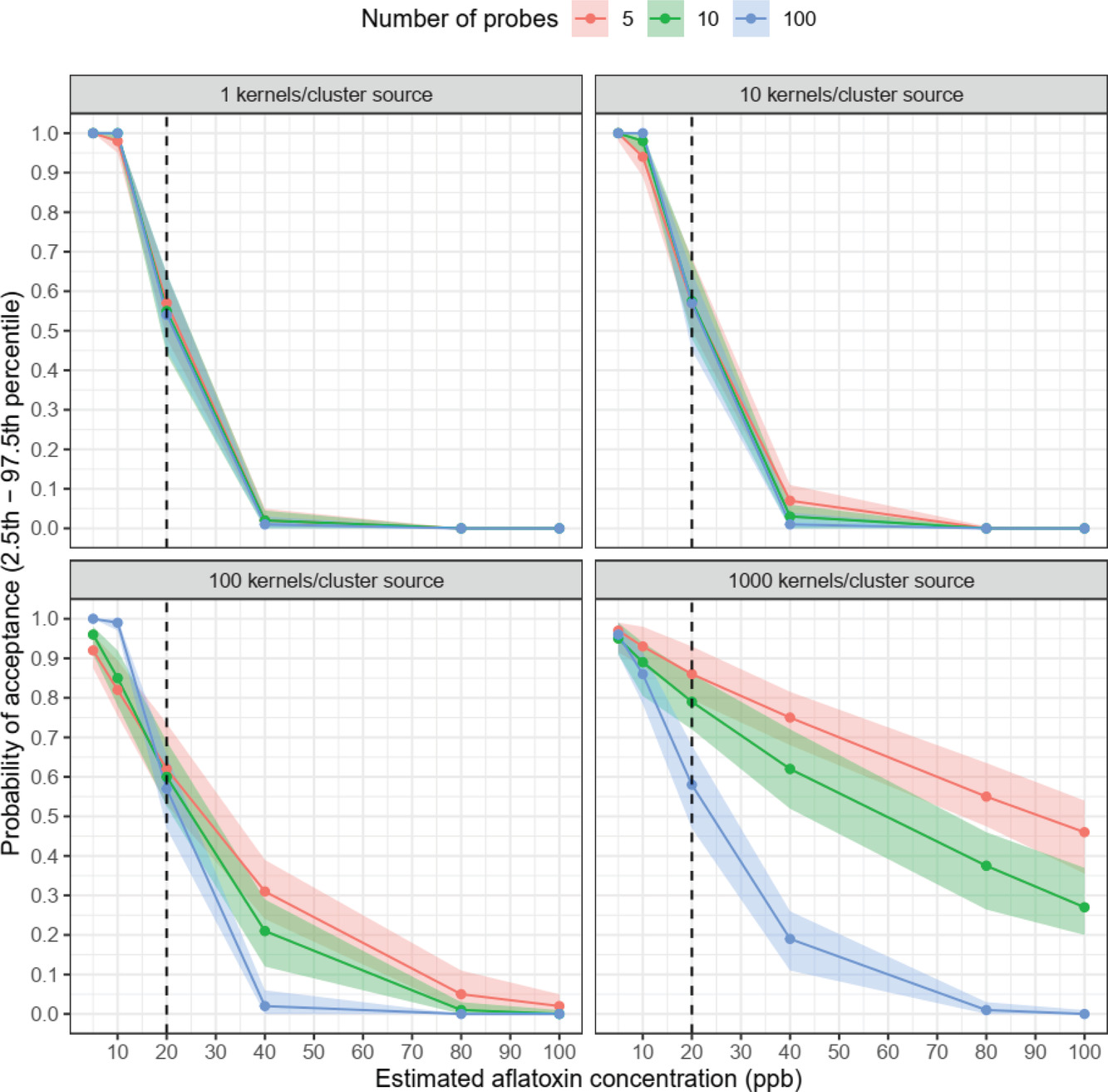
Probe sampling plans for aflatoxin in corn attempt to reliably estimate concentrations in bulk corn given complications like skewed contamination distribution and hotspots. To evaluate and improve sampling plans, three sampling strategies (simple random sampling, stratified random sampling, systematic sampling with U.S. GIPSA sampling schemes), three numbers of probes (5, 10, 100, the last a proxy for autosampling), four clustering levels (1, 10, 100, 1,000 kernels/cluster source), and six aflatoxin concentrations (5, 10, 20, 40, 80, 100 ppb) were assessed by Monte-Carlo simulation. Aflatoxin distribution was approximated by PERT and Gamma distributions of experimental aflatoxin data for uncontaminated and naturally contaminated single kernels. The model was validated against published data repeatedly sampling 18 grain lots contaminated with 5.8–680 ppb aflatoxin. All empirical acceptance probabilities fell within the range of simulated acceptance probabilities. Sensitivity analysis with partial rank correlation coefficients found acceptance probability more sensitive to aflatoxin concentration (−0.87) and clustering level (0.28) than number of probes (−0.09) and sampling strategy (0.04). Comparison of operating characteristic curves indicate all sampling strategies have similar average performance at the 20 ppb threshold (0.8–3.5% absolute marginal change), but systematic sampling has larger variability at clustering levels above 100. Taking extra probes improves detection (1.8% increase in absolute marginal change) when aflatoxin is spatially clustered at 1,000 kernels/cluster, but not when contaminated grains are homogenously distributed. Therefore, taking many small samples, for example, autosampling, may increase sampling plan reliability. The simulation is provided as an R Shiny web app for stakeholder use evaluating grain sampling plans.